A Case Against Training Your Own LLMs
(Unless You’re an AI Lab)
The Reality Check
GPT-4 is estimated to have over 1 trillion parameters, while GPT-3.5 has 175 billion parameters and offers fine-tuning capabilities. This raises an important question: Can smaller, custom-trained models truly compete?
Consider this scenario:
- You hire a team of 10 people
- Invest in expensive GPU infrastructure
- Navigate the complexities of CUDA and PyTorch
- Finally achieve a model that performs well on your specific task
Then suddenly, a major AI lab releases a model that’s both 10x better and half the price. Meanwhile, someone using clever prompting achieves similar results to your custom model without any training costs.
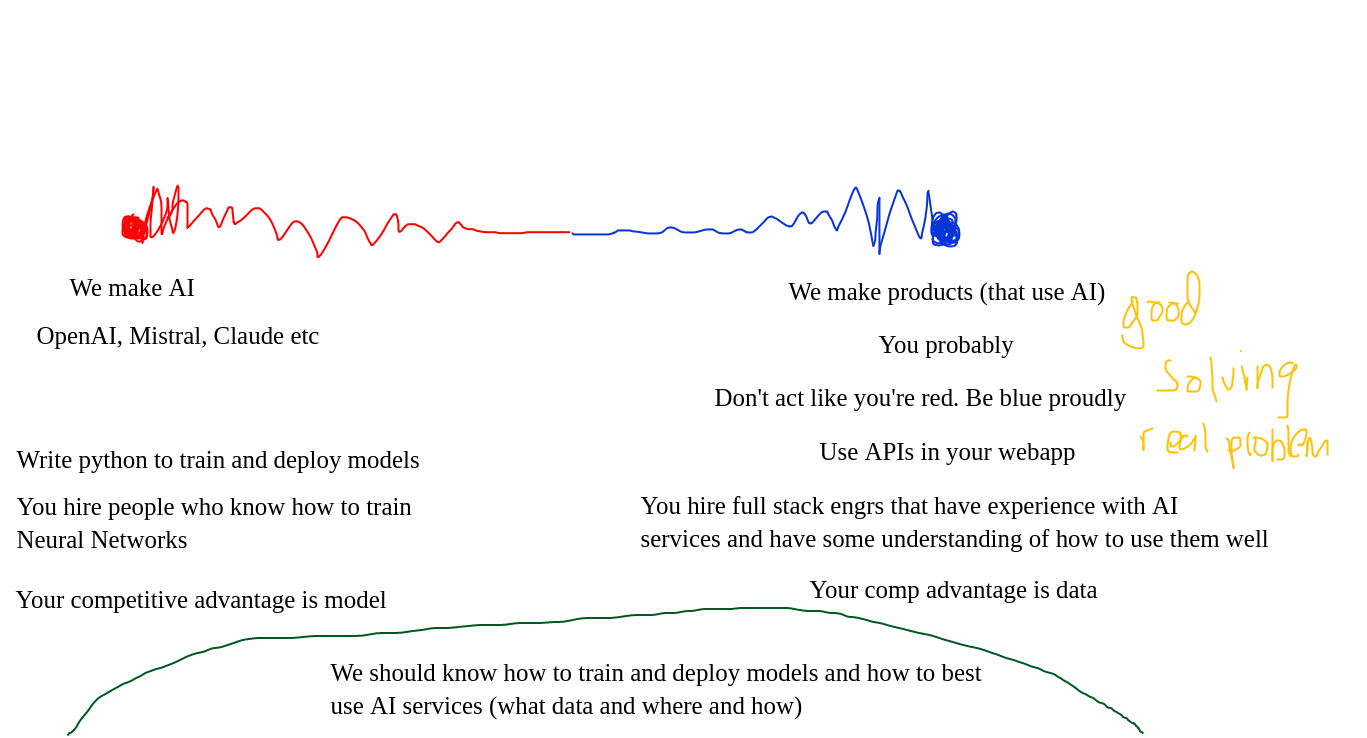
The Better Approach
Stop trying to compete with AI labs and start thinking long-term about your customers’ needs. Having the technical ability to train LLMs doesn’t mean it’s the right business decision.
Common Objections
Q: “It’s just a GPT wrapper.”
A: If your product’s barrier to entry is that low, that’s on you. Everyone has access to LLM providers, just like cloud providers - we don’t dismiss cloud-based services as “AWS wrappers.” Focus on your unique value proposition.
Q: “We’re too dependent on OpenAI.”
A: You mean dependent on AWS or GCP? If you’re concerned, maintain backups (Gemini, Claude, Meta, etc.).
Q: “Investors won’t fund us without custom models.”
A: Those investors likely don’t understand the space. Building custom models for the sake of fundraising is a short-sighted strategy.
Q: “What value are you adding if you’re just using an API?”
A: We’re delivering the best possible solution to our customers. Success isn’t about technical complexity - it’s about serving people’s needs effectively and efficiently.